Meta AI has unveiled its latest breakthrough in generative AI technology for speech – Voicebox. This novel model excels in generating high-quality audio clips across a wide range of tasks and styles, an ability unseen in prior models. This multi-tasking capability has set a new benchmark in the field of AI-generated speech.
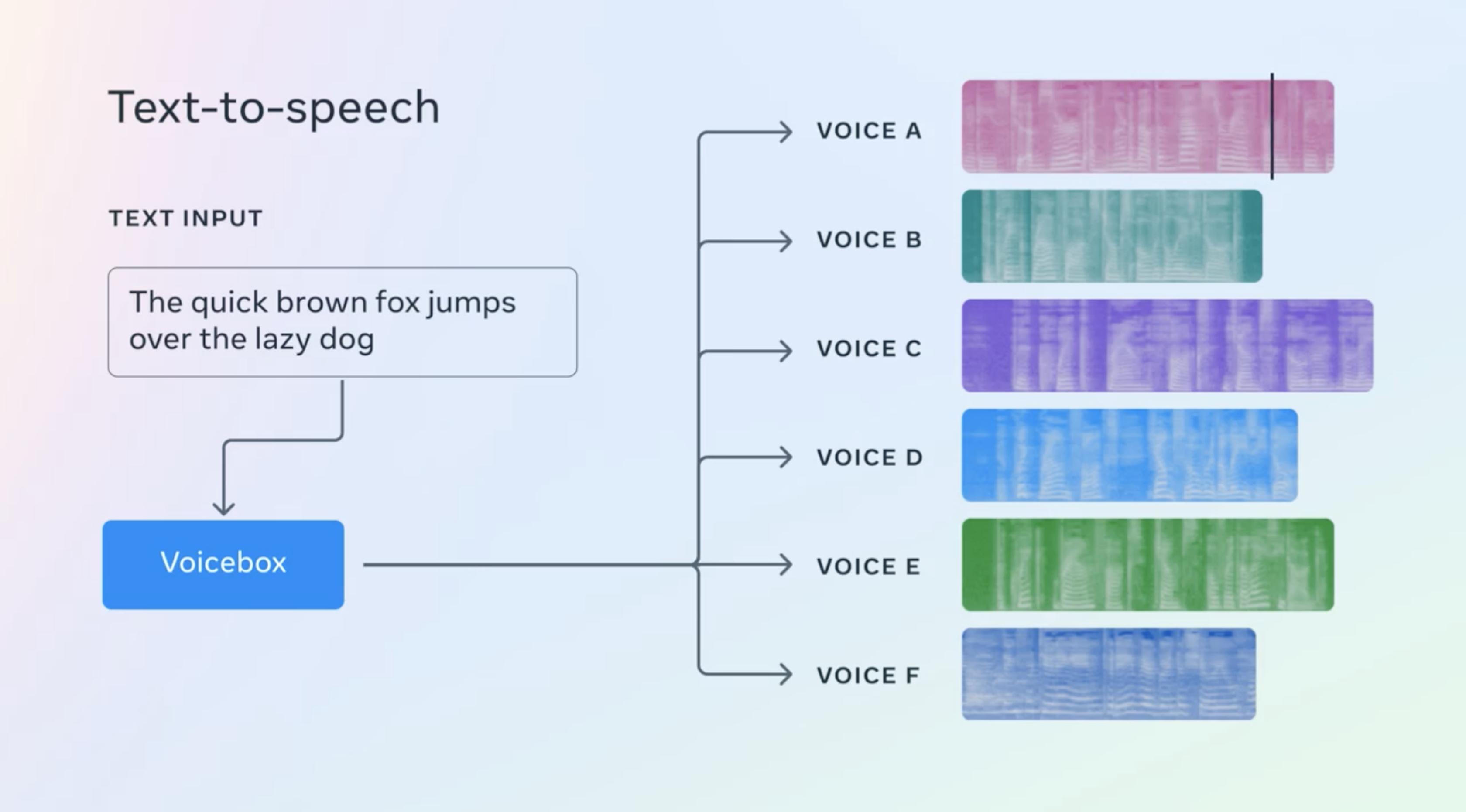
Generative systems for images and text have been known to create outputs in numerous styles, as well as modify given samples. Voicebox is bringing this flexibility to the realm of speech, capable of creating content from scratch or making adjustments to an existing sample. This revolutionary technology can synthesize speech in six different languages and also accomplish tasks such as:
- Noise removal
- Content editing
- Style conversion
- Diverse sample generation
Previous speech-generation AI required specific task-based training using painstakingly prepared data. Voicebox represents a significant shift from this paradigm, learning solely from raw audio and a matching transcription. Unlike traditional autoregressive models, Voicebox can alter any part of a given sample, not just the end of an audio clip.
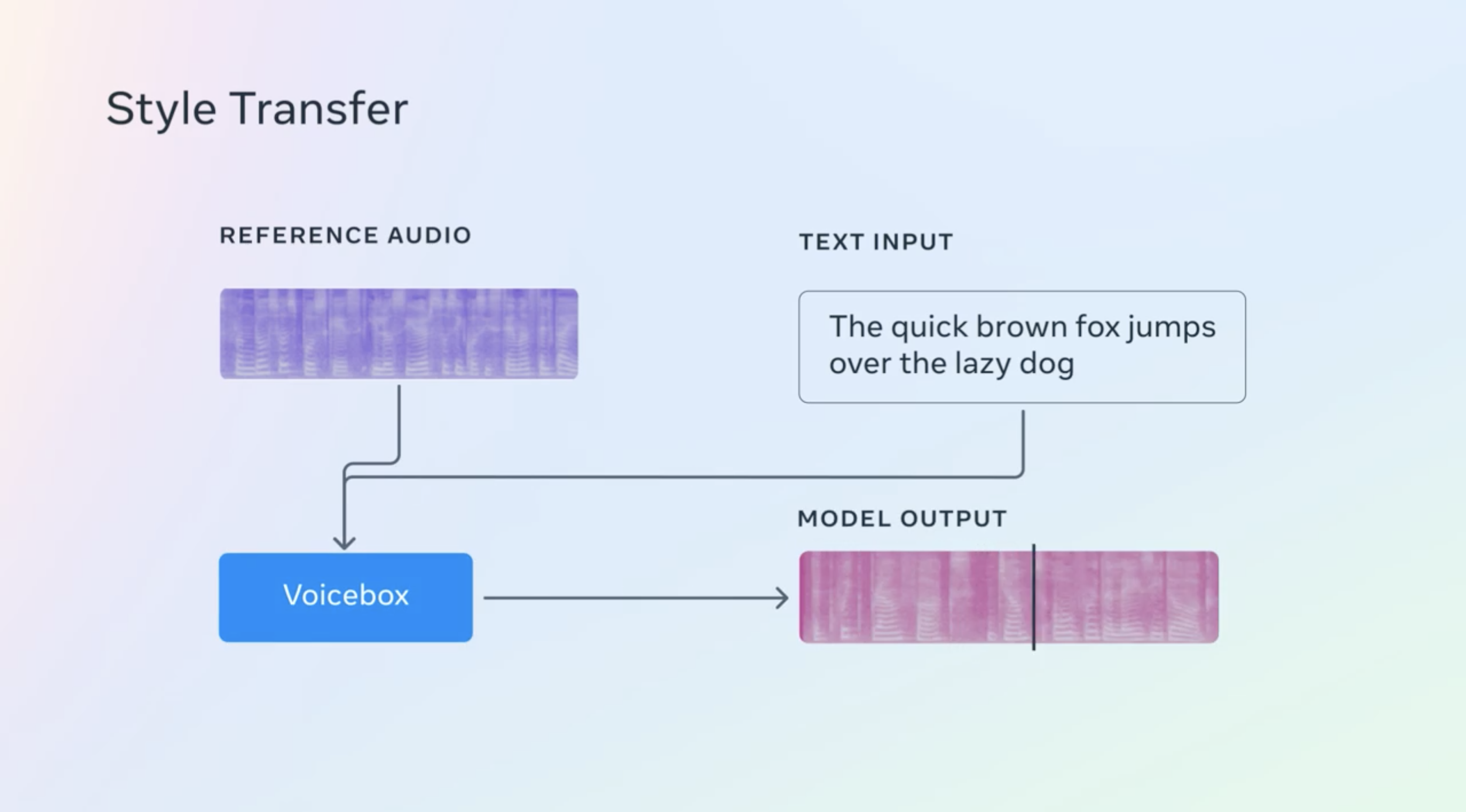
The underlying method behind Voicebox is Flow Matching, a technique that has demonstrated an edge over diffusion models. In comparative tests, Voicebox outdid the leading English model, VALL-E, on zero-shot text-to-speech, delivering superior intelligibility and audio similarity. It was also significantly faster – up to 20 times. In cross-lingual style transfer, Voicebox surpassed YourTTS, reducing average word error rates and enhancing audio similarity.
The creators of Voicebox, however, have taken a responsible approach to its release. Given the potential for misuse, Meta AI has decided against making the model or its code available to the public at this time. The company is keen on striking a balance between openness and responsibility in AI research. Therefore, while withholding the model, Meta AI is sharing audio samples and a research paper detailing their innovative approach and its stellar results.
Transformative Approach to Speech Generation
Voicebox is taking generative AI for speech to new heights, introducing an innovative approach that overcomes the restrictions of existing speech synthesizers. Prior models were primarily trained on data explicitly prepared for the task, a process that proved arduous and resulted in outputs that often sounded monotonous.
Voicebox, however, was built on Meta's Flow Matching model, the latest in non-autoregressive generative models. This allows Voicebox to perform non-deterministic mapping between text and speech, enabling it to learn from a variety of speech data without the need for intricate labeling.
A New Standard in Multilingual Speech Synthesis
With training based on more than 50,000 hours of recorded speech and transcripts from public domain audiobooks across six languages (English, French, Spanish, German, Polish, and Portuguese), Voicebox has set a new standard in multilingual speech synthesis. The model's learning capability extends beyond infilling speech from context to applying this knowledge across a variety of speech generation tasks.
Unprecedented Versatility in Speech Tasks
Voicebox's groundbreaking versatility enables it to perform multiple tasks with excellence, including:
- In-context text-to-speech synthesis
- Cross-lingual style transfer
- Speech denoising and editing
- Diverse speech sampling
This feature provides immense potential for future projects, such as creating speech for those unable to speak or customizing the voices used by nonplayer characters and virtual assistants.
Responsible AI Development and Future Outlook
Meta AI is mindful of the potential risks Voicebox could pose in terms of misuse and unintended harm. As a precaution, they've designed an effective classifier to distinguish between authentic speech and audio generated by Voicebox.
Voicebox vs. ChatGPT
While Voicebox and ChatGPT are both significant achievements in AI technology, they serve distinct purposes. Voicebox, developed by Meta AI, is a generative model for speech, capable of synthesizing high-quality audio clips and performing a range of tasks such as noise removal, content editing, and style conversion. On the other hand, ChatGPT, developed by OpenAI, is a large language model that generates human-like text based on the prompts it's given. It's primarily used for text-based tasks like conversation generation, content creation, and answering queries.
The key difference lies in their modalities: while Voicebox operates in the realm of audio, generating and manipulating spoken content, ChatGPT is focused on text. However, a synergy of such models could lead to intriguing applications, such as a fully AI-generated and moderated audio chat, complete with varied accents, styles, and languages. Both models reflect the vast potential and diversity of tasks that AI can assist with and enhance, pushing the boundaries of human-computer interaction.
How to use Meta AI's Voicebox
Despite the detailed specifics of Voicebox's capabilities and applications, Meta AI has not yet released the model or its code to the public, considering the potential risks of misuse. Therefore, direct usage of Voicebox is currently not available. However, Meta AI is committed to sharing its research, findings, and audio samples with the broader scientific community. This could enable AI researchers and developers to better understand Voicebox's methodology and achievements, potentially informing their work on similar projects or applications. The ultimate aim is to further the progress of generative AI for speech while maintaining a responsible approach to its development and deployment. More updates regarding its utilization will likely be announced by Meta AI in the future.
